

In the previous post we looked at some high-level techniques you can use to prevent errors from arising in the first place, but there are all sorts of errors which we simply cannot avoid. If we can’t prevent a particular failure, the next best thing is to handle it gracefully.
In this post we’ll explore some common patterns for handling certain well-defined failures, and also touch briefly on methods for dealing with more general failures.
The key is to understand that specific failures can often be anticipated, and therefore handled. If we know exactly where and when we’re expecting something to go wrong, then we can build resilience around it (this is often referred to as “defensive coding”).
Even when we don’t know exactly what will go wrong, there are still steps we can take to catch errors and react to them sensibly, so that our whole system doesn’t blow up at the first sign of failure.
Resiliency patterns
To begin with, let’s look at some standard resiliency patterns and techniques you can apply in a variety of common situations.
Retries
The most obvious response to something not working the first time is to just try again. Retries are simple and effective, especially for things like network calls which are famously unreliable.
However, you should be careful, as trying again is not always an option. In some cases a failure may occur even when the intended operation succeeded, in which case you may not want to risk repeating it. For example, if you send an HTTP request to charge a customer’s credit card and it fails due to a timeout, do you risk sending another one and potentially charging them twice?
This is a common problem, but it can be avoided if the operation is designed to be idempotent. An idempotent operation is one that has the same effect whether it’s performed one time or multiple times. Many popular APIs will have some sort of idempotency mechanism built in to make retries safer. Taking the example from above, the payment provider Stripe solves this exact problem with what they call idempotent requests.
Exponential backoff
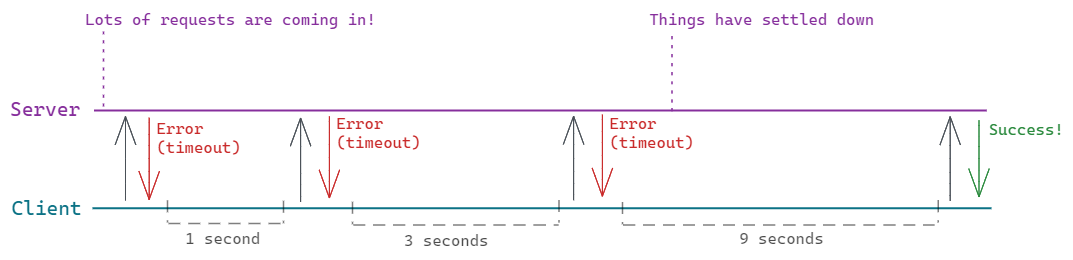
If an operation is failing, it may be because a resource at the other end of it is busy or overworked. If you continuously retry without waiting, you may well be contributing to the problem. As such, it’s often wise to implement an exponential backoff process whenever you have retry logic in place. This just means waiting longer and longer between each successive attempt, to avoid generating excessive load.
[In this example the server is under heavy load, but an exponential backoff approach by the client allows it time to recover.]
Circuit breakers
If calls to some external service start failing, you could just keep retrying until they succeed. But after a certain number of retries, it’s likely that the system at the other end is suffering a real outage. By continuing to make requests, you could be generating additional load and making the problem worse.
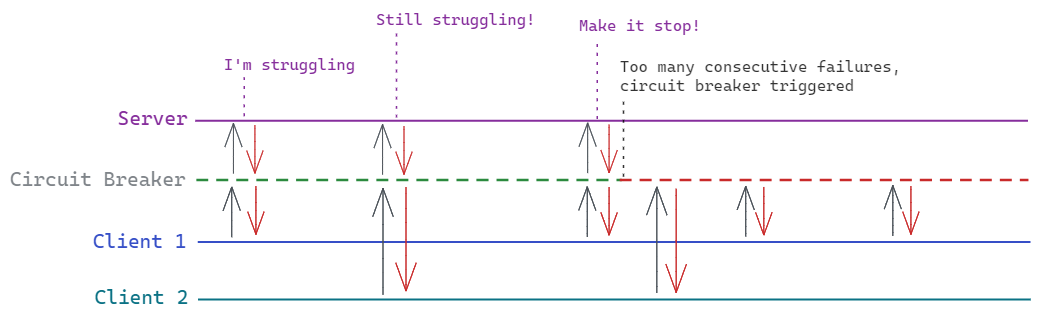
The circuit breaker pattern is about adding a wrapper around the external service, which takes in and passes along requests. If the service starts failing consistently, the wrapper stops forwarding requests to it for a certain period of time - instead it “short-circuits” them and raises an error to the caller immediately.
[In this example the server is again under heavy load, but this time the circuit breaker kicks in after too many consecutive failed requests, to shield the server from being hammered by multiple clients.]
At this point it’s worth highlighting a fantastic library for .NET called Polly, which makes it very easy to configure circuit breakers, retries, and a whole host of other resilience mechanisms. We’ve used Polly on a number of projects here at Ghyston and can strongly recommend it.
Bulkheads
A single application might be formed of several separate but related services. You may not want your entire application to stop working in the event that one of the services goes down. For example, you might have one service that’s responsible for taking and processing orders, and another that generates product recommendations. If the product recommendation service goes down, you don’t necessarily want to stop accepting orders.
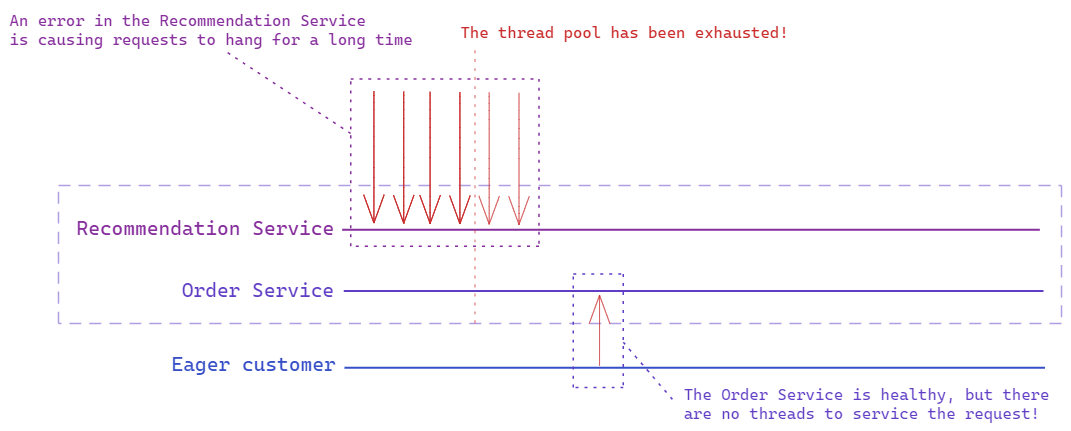
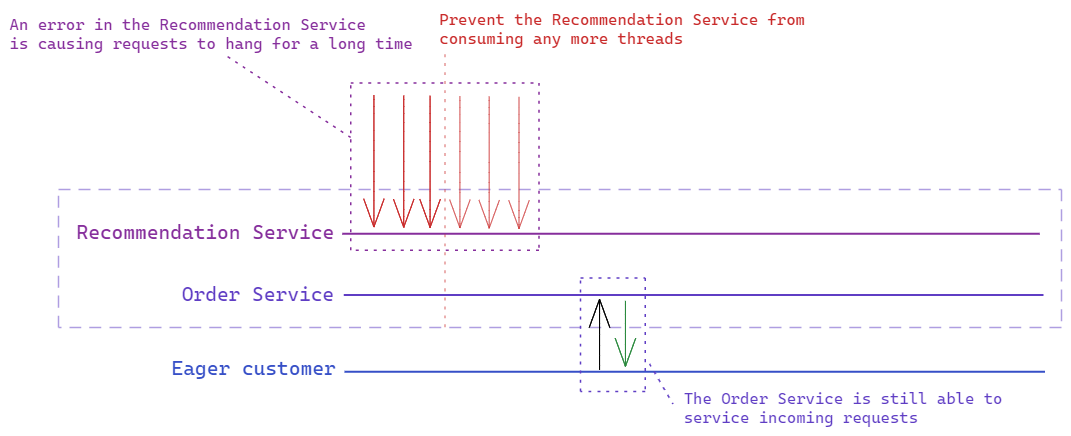
The bulkhead pattern is essentially about isolating the different parts of your system, so that a failure in one area doesn’t cascade through to the rest of your application. This commonly involves limiting the resources a single service/operation can consume, so that if it starts failing and requests back up there are still resources free to allow the rest of the system to continue operating.
[In this example there is no bulkhead, so a failing Recommendation Service eventually consumes all available threads and the whole system stops responding.]
[In this example a bulkhead is limiting the number of threads the Recommendation Service is allowed to consume, so there are still threads available to handle requests to the rest of the system.]
Transactions
When dealing with multi-step processes, how do you ensure that your system remains in a consistent state if some operations succeed but others fail? Database transactions can (and should) be used to solve this problem in the specific context of database operations, but more generally things are a lot harder.
Database transactions are designed to have a number of properties (atomicity, consistency, isolation, and durability), which are often referred to with the acronym ACID. If you’re trying to implement your own “transaction” in a non-database context, then these properties can serve as a good reference. However, transactional behaviour is sometimes all but impossible to achieve, especially in distributed systems, and as such you may need to take a different approach (such as aiming for eventual consistency).
The issue of consistency is a complex one, which could easily provide content for several blog posts. We won’t dig any deeper here, but for an entertaining and informative exploration of this thorny issue I recommend watching Jimmy Bogard’s talk on Six Little Lines of Fail.
Escalation techniques
Computers are good at handling certain situations if you tell them exactly what to do, but inevitably situations will arise that they haven’t been designed to handle. Writing resilient code allows your application to handle most failures by itself, but some failures can only be properly dealt with by a human. For this reason it’s absolutely crucial to have escalation processes in place.
Sometimes it’s sufficient to merely surface errors in a sensible way, providing just enough detail for someone to take corrective action. For example, suppose you have a system that pulls data from a CMS and an operation that relies on that data. If the data is incorrect or incomplete, you want to inform the user of that when the dependent operation fails, so that they can go into the CMS and fix it. If all the user sees is an error message saying “Oops, something went wrong”, then they’ll have no way of knowing how to handle the failure.
You may also want to consider building manual intervention and/or override mechanisms directly into your application if there are certain processes where it’s frequently unclear what action should be taken. Allowing administrative users or support staff to easily take over and handle things if something goes wrong is really important in these sorts of situations.
Summary
In this post we looked at some practical tools and techniques you can use to fight back against failures by handling those you can reliably anticipate.
The key takeaway is that you should always be thinking about what could go wrong in your system, and deciding whether it’s possible to handle failure cases gracefully. There are some well-known situations in which trouble can be expected, such as when interacting with the network, but it’s also important to identify risky operations that are application-specific.
It’s also worth noting that, as with prevention methods, the “Swiss cheese” analogy holds true. It's not just a case of picking one pattern to use - you need to apply a combination of techniques, and have them work together to handle different situations.
You’re now equipped with a number of weapons for preventing and handling failures, but in the real world errors inevitably crash through despite our best efforts. In the next post we’ll round off the series by looking at some tools and techniques for mitigating failures that slip through our safety nets.


