

Software is both an asset and a liability: it’s an asset because it helps you operate effectively and efficiently and it can be your ‘edge’ against the competition; but it’s a liability because it needs to be maintained. This is the case for bespoke software even more than off-the-shelf software. Bespoke software can deliver significant advantages over off-the-shelf,and one of those advantages is that when you want to evolve your business processes to seize a new opportunity or to do things even better, or to handle environmental changes like changes to suppliers or regulations, then you have full power to evolve the software accordingly, without being beholden to a supplier’s roadmap. These changes may be big or small, and generally get bundled into ‘maintenance’.It seems clear to us that any bespoke system should be built to be easily maintainable, so that it can be easily adapted to meet changing needs over time, and remains fit for purpose over a lifetime of years. Unfortunately, we find that maintainability is regularly overlooked. Its benefits aren’t immediately obvious to stakeholders and users, compared to pressing concerns such as delivering functionality and meeting project deadlines. When it’s not given due attention, then before long, making a small change requires a new developer to build up an encyclopaedic knowledge of the entire system in order to not break something inadvertently. This means changes become slow, expensive and risky. Why does this happen, and what can we do to help developers fall into the pit of success?
At Ghyston, a technique we strongly recommend for building maintainable software is to architect your application around Vertical Slices. In this post, we’ll explore how this architecture style works, and how the benefits it gives over a more traditional approach.
What makes software maintainable?
It’s important to make sure that your application architecture pushes your developers to write maintainable code. We’ve found that an effective way to achieve this is to aim for a design that allows changes to be localised to a single component, without needing to make changes across a wide cross-section of the system. This means a developer only needs to keep the details of that single component in their head, which reduces the mental load required to make a change.
There’s a common term describing what we’re looking for here: we want low coupling between the different components of our system, so that they can be changed independently and evolve separately over time.
What impact does our application architecture have on this? Let’s first consider a well-known architecture pattern and see what effect high coupling can have on maintainability.
The Traditional Approach
A common architecture choice is the “layered architecture”, where application code is split into separate layers, based around separate technical roles:
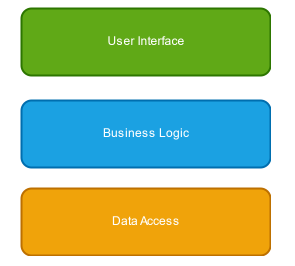
The benefit here is that we achieve a separation of concerns: we avoid polluting the complex business logic code with concerns around the exact way the data is presented to users, or how the data is persisted, and these layers can change independently from each other.
Other variants of this architecture exist, including Clean Architecture or Onion Architecture, all driven by fundamental idea of separating code into layers based on some the technical role performed by the code.
These architectures are effective, and many well-designed systems have been created using them. However, when building applications in this way, we found we commonly ran into various problems as the systems grew in size and complexity.
Does our architecture fit our mental model?
Let’s take a closer look at what’s happening within each layer. A common approach is to identify the key “entities”, or concepts within the business domain, and group related functionality based around the entities within each layer.
For example, consider a system tracking tournament statistics in the Ghyston office pool tournament. We’d group code within each layer, based on whether it’s related to players, or to games:
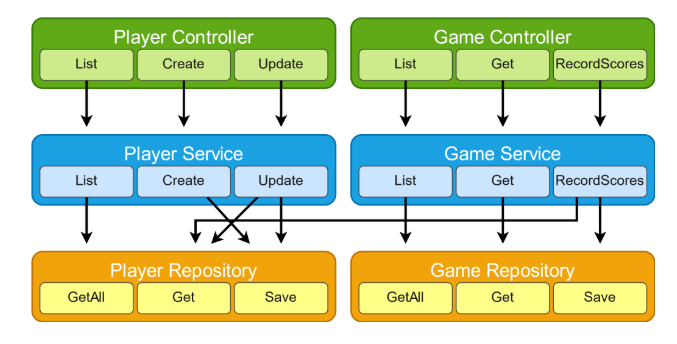
Suppose we realise that there’s a bug in how we handle updating players. The implementation for this single unit of functionality is split across each layer. To resolve the bug, a developer will need to dig into the related code in each layer, and might need to make changes across all three layers.
We’ve separated out our code into separate layers, to allow them to change independently. However, in reality, our changes are made across all the layers together. By decoupling the layers, we’ve actually made life harder for ourselves: to make the change we need to hold information about all three layers in our head at once.
Typically, we think about how the application’s code in terms of its features, and how they fit together. We don’t think about it in terms of which layer the code sits in. We’ve introduced an impedance mismatch here: our application architecture doesn’t match how we think about the application as a whole.
Tight coupling
Within each layer, we group code based on which entity it relates to. Each entity type has a corresponding service responsible for holding all business logic related to that entity, and a repository responsible for all data access related to the entity.
In practice, we’ve found that this grouping leads to services and repositories growing to unwieldly sizes. Each class ends up with many different methods, corresponding to every action a user can take in the system. From a pure code standpoint, this is hard to work with: it’s tough to find the correct method in a class spanning hundreds of lines.
There’s a subtle, insidious problem that arises here. It’s tempting to apply the principal of Don’t Repeat Yourself, identifying common code that’s duplicated between different parts of a service, and commonising that duplicated code into a single method. This is a well-reasoned approach: duplicated code can be a source of bugs, as a fix to one area of code might not be applied to another. However, whenever code is merged like this, we introduce tight coupling: if a change is made to the shared code, it affects everywhere that code is used.
In practice, we often find that the separate branches of functionality have different fundamental reasons to change, and need to be changed independently. It may be that different types of user, who once had similar requirements, now want different views of the data. We thought we were making things easier to change, but now it’s much harder! Even worse, we may change the code and not realise it’s depended on by other system components, causing unintended knock-on changes.
Our application architecture has made it easy for us to introduce coupling, which will only make our life harder in the long run. This isn’t ideal - we want to make this sort of behaviour harder, not easier! Code re-use should be an explicit decision requiring consideration, made only when it’s warranted.
Cross-entity concerns
Suppose we want to add a feature to our tournament application to track a rating score for each player that changes as they win and lose games. Let’s think about how we would do this: we know we need to update the logic in GameService used to record game scores, so that we also update the player’s rating. A rating is a player-related concept, so it would make sense to live in PlayerService. To keep consistency, we need to split this logic across multiple services. In future, when another developer needs to make a change, they now need to look at multiple different services and jump through more mental hoops just to understand what the code is doing.
We run into problems when it’s not always clear-cut which entity an operation is related to - where should something that modifies multiple different entity types live? Our code organisation model isn’t flexible enough to model our business domain in its entirety. Whichever way we pick, it’s likely to confuse someone as it means the code isn’t exactly where they expect it to be.
Re-thinking our approach
We’ve seen various pain points caused by how we’ve architected our application to group code based on its technical layer, and based on which entity type it relates to. What if we take a step back, and consider if there’s a different approach we could take?
Grouping code based on entity types has led to services growing too large, containing many independent pieces of functionality. Can we break these up into smaller pieces? The diagram above gives a clue for how to decompose the services: we can break them up into each separate action that can be performed by a user. Within a web application, this lines up with separating out the code corresponding to each different web request. We create a separate class corresponding to action. We’ll call these handlers, to distinguish from services, and to express the intention that they each handle a certain action.
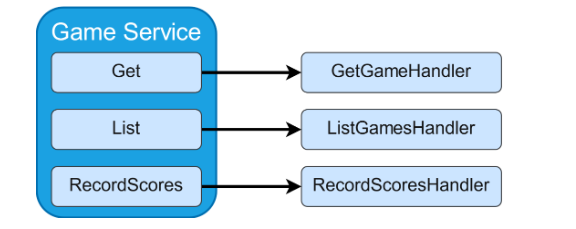
What do we do with the separate layers of code? We can take the idea of splitting things up based on the actions in the system even further: why not group everything related to a single action into one place? We can group together the business logic, data access, domain transfer objects, and everything else.
Rather than thinking about code based on its technical role, we’re now thinking about code based on features. Each feature covers a vertical slice of the application.

This is the “Vertical Slice Architecture”. Our application architecture now more closely mirrors how users interact with the system: we’ve made those user interactions the building blocks of our code.
How well does this fit with what we set out to achieve? We’ve emphasised each separate feature in the system being a separate component, and so in particular each feature can be changed independently. By explicitly separating out each slice, we’ve minimised coupling between the separate features, as we wanted. Within each slice, the code all relates to a single feature, and so is internally cohesive, and can be changed together to match the changing requirements of the system.
There is a downside - it’s not immediately obvious how we can share code between slices. As it stands, we’re going to potentially have code duplicated between slices. It is possible to extract out shared code into another class and use it from multiple slices, but this is harder than it would have been had the logic been grouped together in the first place. We’ve found that adding this trade-off works out in the long run, as the explicit barrier to code re-use ensures developers only introduce coupling between slices when they explicitly intend for that to be the case.
As we’ve applied this architecture on multiple different projects, we’ve found its benefits really become apparent during the maintenance phase of those systems. We’ve been able to make continued changes to the systems quickly and easily, and so this has become our preferred architecture for building maintainable software. We’d really recommend you try it out as well!
Further reading
If you’re interested in learning more about the topic, check out Jimmy Bogard’s talk on Vertical Slice Architecture, using his MediatR library. We’ve found MediatR to be a very good fit for .NET projects using this architecture pattern. It allows modelling each vertical slice as part of a request pipeline, can be used to handle cross-cutting concerns such as automatic transaction handling and validation around each request.
For an example implementation of this pattern, see this example, also from Jimmy Bogard.


